last 2010 huzzah
2010 was a bit of a roller coaster...
First, the passing of four very good friends and colleagues:
- John Alexander Wildgoose, a fellow dba and IT pro as well as my long time golf buddy and friend.
- Dr. Paulo Abrantes, a very good adolescence friend I hadn't seen in many years, who quietly passed away recently. I do miss our talks about the future, Paulo.
- Noel Vanspaal, my database technology mentor and someone I respect professionally more than any other. Over more than 25 years Noel always had a moment to discuss any weird and wonderful issue I came up with, often followed by the sharing of a fiery curry from his native Madras, prepared by his wonderful wife Renata. We shared a similar professional background and had a perfect empathy in what relates to database issues and their resolution.
- Carlos Correia, my uncle and fishing mentor who also got me into the DIY bug and taught me how to catch just about any fish in any situation.
Vale, each and every one of you. I miss your presence and company but your friendship and fellowship will never leave.
And please: can it stop now? Had enough losses, thank you...
.
.
.
On the other hand I have had the great fortune and joy of meeting again many of my high school friends and colleagues from East Timor and some from my native Mozambique.
Amazing how our lives have branched out from each other, and yet after all these years we could still find so many things in common.
We are now all in touch regularly through Facebook and other social networking sites. And that has helped tremendously in coping with the above losses.
Still, that's all beyond the purpose of this blog. Meant more as an explanation of why it's been so hard for me to find the time to come here and talk about dba work.
On this one, I just wanted to show you the sort of performance we're getting in our main DW production node. Please understand: this is not some fancy-shmancy multi-million dollar RAC environment with everything in hardware-land thrown at it and infinite cost limits.
Far from it.
It's a simple Aix LPAR (a Unix VM in IBM parlance) with between 2 and 4 cores assigned to it, varying with the load we put on the system overall.
In this same box we run two i-series JD Edwards databases and applications, two other smaller Oracle databases and the main DW (1.8TB of it). As well as a SOA app server.
On the storage front, we have a Clarion SAN shared with every other server in our data centre.
Let me just stress that out again in case it was not clear: EVERY OTHER server.
That's Aix, Linux, Windows, you name it.
Yes.
You see: we like to run our data centre as a private cloud.
It was that way, long before this expression became common place with people who haven't got a clue what weather patterns are...
So, let me see: the performance has to be abysmal, right?
Because in-house is necessarily bad: outsourced services are much more "specialized" and "cost-efficient", isn't it?
Well, not just quite. You see: it's not enough to quote from "white papers".
I submit the following to your appreciation. It is a 30 second summary sample of the "topas" tool supplied with Aix, from our DW database node. Taken the 24th Dec 2010, around lunchtime. A timeframe that I'd dare suggest is slightly "idle" by definition.
Here it is:
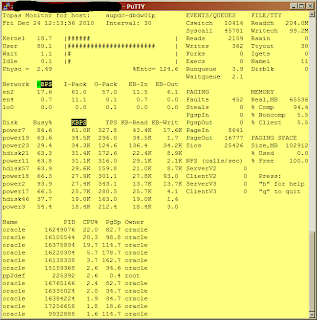
Most Oracle experts nowadays claim that one CPU core is capable of 200MB/s sole absolute max I/O capacity. That's assuming it's not doing anything else.
We have 2 cores here busy as heck with PL/SQL packages. I'd dare say 300MB/s of aggregate mixed reads and writes - that's MegaBytes per second, Virginia! - sustained over a period of 30 seconds WITH an average of 1.1% I/O wait time, is not bad at all.
That's on an idle Xmas eve, in a server that cost half a megabuck and is being shared with 5 other applications and everything and the kitchen sink in the SAN.
I may be an eternal optimist but this nicely fits my definition of "running very well, thank you!".
Check out the number of luns involved in the I/O and the iops and MB/s each is pumping. Pretty even, eh?
But you should listen to the SAN experts telling me I should "balance my I/O". And the Oracle "experts" telling me I should use ASM/RAC/whatever-technology-de-jour they are flogging that week.
Interesting that NOT ONE of those "experts" has EVER asked to see the performance figures of the system.
They just jump straight into "it must be bad" mode.
On a really busy day this system pumps out in excess of 500MB/s, with around 5% I/O wait time aggregate for periods in excess of 1 hour, solid.
But you should hear the "architects" I've been seeing in the last three months telling me the performance would be much better if we outsourced our systems to people who are "experts" on the subject. For a "lot less cost", of course.
(Interestingly, NOT ONE of them has asked to see the actual current system and its performance figures...)
I suppose that'd involve using a cloud as well because it is "cheap"?
Hang on, but we ARE using a cloud! And we have shared the cost of this infrastructure with our ENTIRE data centre storage resources. Prove to me you can do it cheaper first!
Hey, I defy ANY "expert" out there to produce a set of figures like this from an EQUIVALENTLY specified system, under the SAME load constraints and sharing the SAME infra-structure cost with everyone else.
And that is the simple reality, folks. Fact, not fiction.
Actual load figures. Not white papers.
You see: I like to show results, not theories.
And I demand to see facts backing anyone else's theories.
Nuff said.

Have a great 2011 everyone!
First, the passing of four very good friends and colleagues:
- John Alexander Wildgoose, a fellow dba and IT pro as well as my long time golf buddy and friend.
- Dr. Paulo Abrantes, a very good adolescence friend I hadn't seen in many years, who quietly passed away recently. I do miss our talks about the future, Paulo.
- Noel Vanspaal, my database technology mentor and someone I respect professionally more than any other. Over more than 25 years Noel always had a moment to discuss any weird and wonderful issue I came up with, often followed by the sharing of a fiery curry from his native Madras, prepared by his wonderful wife Renata. We shared a similar professional background and had a perfect empathy in what relates to database issues and their resolution.
- Carlos Correia, my uncle and fishing mentor who also got me into the DIY bug and taught me how to catch just about any fish in any situation.
Vale, each and every one of you. I miss your presence and company but your friendship and fellowship will never leave.
And please: can it stop now? Had enough losses, thank you...
.
.
.
On the other hand I have had the great fortune and joy of meeting again many of my high school friends and colleagues from East Timor and some from my native Mozambique.
Amazing how our lives have branched out from each other, and yet after all these years we could still find so many things in common.
We are now all in touch regularly through Facebook and other social networking sites. And that has helped tremendously in coping with the above losses.
Still, that's all beyond the purpose of this blog. Meant more as an explanation of why it's been so hard for me to find the time to come here and talk about dba work.
On this one, I just wanted to show you the sort of performance we're getting in our main DW production node. Please understand: this is not some fancy-shmancy multi-million dollar RAC environment with everything in hardware-land thrown at it and infinite cost limits.
Far from it.
It's a simple Aix LPAR (a Unix VM in IBM parlance) with between 2 and 4 cores assigned to it, varying with the load we put on the system overall.
In this same box we run two i-series JD Edwards databases and applications, two other smaller Oracle databases and the main DW (1.8TB of it). As well as a SOA app server.
On the storage front, we have a Clarion SAN shared with every other server in our data centre.
Let me just stress that out again in case it was not clear: EVERY OTHER server.
That's Aix, Linux, Windows, you name it.
Yes.
You see: we like to run our data centre as a private cloud.
It was that way, long before this expression became common place with people who haven't got a clue what weather patterns are...
So, let me see: the performance has to be abysmal, right?
Because in-house is necessarily bad: outsourced services are much more "specialized" and "cost-efficient", isn't it?
Well, not just quite. You see: it's not enough to quote from "white papers".
I submit the following to your appreciation. It is a 30 second summary sample of the "topas" tool supplied with Aix, from our DW database node. Taken the 24th Dec 2010, around lunchtime. A timeframe that I'd dare suggest is slightly "idle" by definition.
Here it is:

Most Oracle experts nowadays claim that one CPU core is capable of 200MB/s sole absolute max I/O capacity. That's assuming it's not doing anything else.
We have 2 cores here busy as heck with PL/SQL packages. I'd dare say 300MB/s of aggregate mixed reads and writes - that's MegaBytes per second, Virginia! - sustained over a period of 30 seconds WITH an average of 1.1% I/O wait time, is not bad at all.
That's on an idle Xmas eve, in a server that cost half a megabuck and is being shared with 5 other applications and everything and the kitchen sink in the SAN.
I may be an eternal optimist but this nicely fits my definition of "running very well, thank you!".
Check out the number of luns involved in the I/O and the iops and MB/s each is pumping. Pretty even, eh?
But you should listen to the SAN experts telling me I should "balance my I/O". And the Oracle "experts" telling me I should use ASM/RAC/whatever-technology-de-jour they are flogging that week.
Interesting that NOT ONE of those "experts" has EVER asked to see the performance figures of the system.
They just jump straight into "it must be bad" mode.
On a really busy day this system pumps out in excess of 500MB/s, with around 5% I/O wait time aggregate for periods in excess of 1 hour, solid.
But you should hear the "architects" I've been seeing in the last three months telling me the performance would be much better if we outsourced our systems to people who are "experts" on the subject. For a "lot less cost", of course.
(Interestingly, NOT ONE of them has asked to see the actual current system and its performance figures...)
I suppose that'd involve using a cloud as well because it is "cheap"?
Hang on, but we ARE using a cloud! And we have shared the cost of this infrastructure with our ENTIRE data centre storage resources. Prove to me you can do it cheaper first!
Hey, I defy ANY "expert" out there to produce a set of figures like this from an EQUIVALENTLY specified system, under the SAME load constraints and sharing the SAME infra-structure cost with everyone else.
And that is the simple reality, folks. Fact, not fiction.
Actual load figures. Not white papers.
You see: I like to show results, not theories.
And I demand to see facts backing anyone else's theories.
Nuff said.

Have a great 2011 everyone!
posted by Noons at 1/06/2011 10:02:00 pm
![]()
![]()


{kind=link}
4 Comments:
The busy percentages on the disks does seem pretty high especially for a time period that you describe as fairly slow.
What kind of average disk read and write times do you get?
Those are LUNs, John. Not "disks".
Disk read and write times are measured in the SAN, not the unix box. They rarely exceed 5milisecs in the SAN stats.
The only thing Unix sees is the LUN. In this case there can be up to 13 disks in each raid stripe and each stripe might be presented as a large number of LUNs.
Busy device percentages are supposed to be high: that's why I get high transfer rates even in idle periods.
We can't get transfer rates solid in the hundreds of MB/s for samples of 30 seconds without making a LUN busy: it is a physical impossibility.
What is important is how much are you waiting for that "busy" to deliver. In this case, 1.1%.
And when it is really busy, there are a LOT more LUNs shown in the device section. It's the totality of those that makes up the aggregate transfer rate.
This is I/O distribution. When it gets busier, more LUNs are involved in the transfers. But at no point does the I/O wait go over 5%.
Which at aggregate transfer rates of 500MB/s I'd call a good result for the type of hardware involved. Never seen any better anywhere, with equivalent setup.
This is not an Exadata box, it's a low-range Clarion shared with everyone else. And the aix box has two AS400/DB2 databases in it pumping away as well.
Like I said: anyone is free to publish better results on similar hardware.
Just claiming these are bad because of some imagined short-coming is however a bit of a stretch...
Of course it is a LUN not a disk sorry just an over simplification.
Where exactly did I claim that the busy rate was bad? I asked a question simple as that ...
I am more used to seeing a %util such as iostat gives you.
In the old days you used to worry about how many requests were queue'd and how busy the device was.
Certainly some levels of indirection now between disks/LUNs and what the operating system on a server is actually seeing and getting reported back to it.
You're absolutely right, of course. My apologies.
Yeah, the queue lengths seem to have fallen by the wayside. Unfortunately. I still think they are one of the best ways of spotting I/O contention.
In fact, in the Wintel world I know of no better!
Queus for disk devices are so common in the MSSQL sphere, it's a given they will happen.
One thing with Wintel I've found makes a difference is the use of various "drive letters", rather than one drive letter with a humongous meta-lun attached to it.
Windows seems to reach a saturation point with dramatical increases in queue lengths at even small disk I/O levels.
I've seen queue length "explosions" in excess of 50 for a single drive letter at something like 60MB/s!
My remedy nowadays for that is:
-split the disk "devices" into multiple presented LUNs - meta-luns, most of the time.
-assign multiple drive letters to each and spread the db across those.
- dedicate one or two of these to the mstemp db.
- and another one to logs.
That seems to bump up the boundary of queue length "take-off" to around 150MB/s, all else remaining equal.
Levels of indirection, you say? You're gonna laugh at this but I'll just describe some of the physical aspects of our setup.
a)- 4th floor of data centre: SAN, plus the VMWare servers, all interconnected to a HP Brocade fabric via dual 4Gbps fibre.
b)- 13th floor: all Aix and MSSQL servers, all connected to SAN via said HP Brocade fabric and dual 4Gbps fibre.
HP Brocade fabric bandwidth capacity? A mistery: apparently they don't worry about those things because it's all "fibre at speed of light".
Speed of light?
Hmmm, what is the switch speed of 4Gbps fc? 4billion switches per second.
How much does light travel in one quarter of a billionth of a second?
Around 10 centimetres, or 1/3 of a foot in imperial measures.
How much distance between a 13th floor and a 4th floor?
I don't know exactly, but I am willing to safely bet it's a LOT more than 10 cms...
Any wonder why I get rabid when I hear the Brocade folks and the data centre folks telling me all this should not affect I/O speed "because it's all done at the speed of light, you know"?
And the show goes on...
:)
Post a Comment
<< Home